

 영중 나
영중 나 
그로스해킹에서 지표 선정의 중요성
그로스해킹은 본질적으로 지표에 관한 일입니다. 서비스의 성장에 가장 핵심이 되는 목표 지표를 정의하고 그 목표 지표를 개선하기 위한 실험을 반복함으로써 결과적으로 서비스의 성장을 이끌어내는 방법론이기 때문입니다. 그렇다면 우리는 어떻게 지표를 정의해야 하고, 또 지표를 정의할 때에는 어떤 점을 주의해야 할까요?
지표의 속성
지표의 속성은 크게 ‘스톡 형태’와 ‘플로 형태’로 나눌 수 있습니다. 스톡 형태는 특정 순간에 관찰하는 누적값이고, 플로 형태는 일정 기간 동안의 누적값입니다.
두 속성의 가장 큰 차이는 기준이 되는 기간이 있는지 없는지입니다. 예를 들어 스톡 형태의 지표로는 누적 가입자수, 누적 거래액과 같이 현재 시점의 순간적인 값이 있고, 플로 형태의 지표로는 1월 1일의 하루 매출, 일주일 평균 방문자 수 등이 있습니다. 많은 경우 단순 누적량만을 보여주는 스톡 형태의 지표는 뒤에서 설명할 ‘허무 지표’인 경우가 많지만, ‘음악 스트리밍 서비스의 음원 보유 수’ 등과 같이 경우에 따라서는 스톡 지표가 유의미한 평가 기준이 될 수도 있습니다.
지표 정의
지표의 속성을 정했다면, 그 다음으로 해야 할 일은 측정할 수 있는 형태로 지표의 조작적 정의를 하는 것입니다. 예를 들어, 우리의 목표 지표가 ‘웹사이트 전환율’이라고 한다면 다음과 같은 질문을 통해 측정의 기준을 세울 수 있습니다.
- 측정 기간은 언제부터 언제까지인가?
- 전환은 어떻게 정의할 수 있는가?
- 웹사이트는 PC와 모바일을 모두 포함하는가?
- 전환의 주체는 회원에 한정하는가? 비회원을 포함한 모든 방문자인가?
- 모든 방문자에 대한 전환율인가? 로그인한 회원에 대한 전환율인가?
- …
이런 질문들을 거치면 ‘웹사이트 전환율 = 오늘 PC 웹사이트에서 구매 결제를 완료한 회원 수 / 오늘 PC 웹사이트에 로그인한 회원 수’와 같은 수식이 만들어집니다. 기준의 우선순위를 세우고 그것을 측정할 수 있는 형태로 정의해야만 모든 구성원이 오해하지 않을 수 있는 원칙이 세워지고, 이 원칙을 통해 같은 목표를 달성하기 위한 가설을 세울 수 있습니다.
지표를 선정할 때 하기 쉬운 실수 TOP 5
그로스해킹을 하기 위해 지표를 측정하고 해석하다 보면 종종 통계의 함정에 빠지곤 합니다. 이런 실수는 데이터를 왜곡하고 잘못된 의사결정을 유도하여 서비스 성장을 저해하는 요인이 되기도 합니다. 우리가 그로스해킹을 하면서 빠지기 쉬운 5가지의 실수를 소개합니다.
허무 지표
허무 지표는 행동을 이끌어내지 못하는, 의미 없는 지표입니다. 대표적으로는 누적 다운로드 수, 누적 방문자, 누적 페이지 뷰 등이 여기에 속합니다. 대부분 시간이 지나면서 자연스럽게 높아질 수밖에 없는 지표이거나 서비스의 성장과 거의 관련이 없는 지표들입니다. 앞서 언급한 스톡 지표 중 상당수가 이런 허무 지표일 가능성이 높습니다.
전체 관점에서의 최적화
나무에 집중하다가 숲을 보지 못하는 경우가 있습니다. 이런 일은 특정 지표에 매몰되거나 단기적인 이벤트를 진행할 때 자주 발생합니다. 예를 들어, 특정 페이지의 CTR을 올리는 데에만 집중하다가 전제 퍼널에서의 전환율이 떨어지는 경우를 들 수 있습니다. 이런 실수를 피하기 위해서는 목표 지표를 선정할 때 다양한 변수들을 폭넓게 고려해야 합니다.
심슨의 역설
우리는 데이터에서 인사이트를 찾기 위해 전체 데이터를 보기도 하고, 데이터를 쪼개서 보기도 합니다. 심슨의 역설은 특히 데이터를 쪼개 볼 때 자주 발생하는데, 쪼개진 데이터에서 성립하는 관계가 합쳐진 데이터에서는 반대로 나타나는 현상입니다.
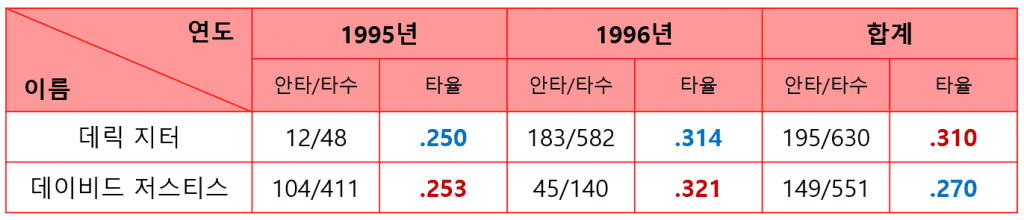
위 표는 미국 메이저리그의 야구선수 데릭 지터와 데이비드 저스티스의 1995년~1996년 타율 데이터입니다. 1995년과 1996년 모두 데이비드 저스티스의 타율이 더 높지만, 2년 동안의 통산 타율을 계산해 보면 데이비드 저스티스의 타율인 2할 7푼보다 데릭 지터의 타율이 3할 1푼으로 더 높은 것을 관찰할 수 있습니다. 이와 같이 심슨의 역설은 표본 개수의 차이나 우리가 발견하지 못한 숨겨진 변수(‘교란 변수’라고 부릅니다) 등에 의해 발생하곤 합니다.
평균의 함정
1985년 노스캐롤라이나 대학교 지리학과 졸업생의 평균 초봉은 10만 달러(한화 약 1억 3천만 원)였습니다. 이 어마어마한 연봉이 나온 이유는 노스캐롤라이나 대학교 지리학과를 졸업한 마이클 조던이 시카고 불스에 입단하면서 받았던 연봉이 데이터에 함께 포함되어 있었기 때문이었습니다.
‘평균’이라는 말을 사용할 때 우리는 보통 산술평균을 생각하곤 합니다. 하지만 산술평균은 정규분포의 형태를 가지는 데이터에서만 대표성을 지닐 수 있을뿐더러 아웃라이어를 설명할 수 없기 때문에, 오히려 많은 경우에 중앙값이 더 안정적인 대표성을 가집니다.
생존자 편향의 오류
잘못된 데이터를 활용하면 결과값도 제대로 나올 수 없습니다. 데이터 분석 분야에서 유명한 격언인 ‘Garbage In, Garbage Out’이 이와 같은 의미입니다.
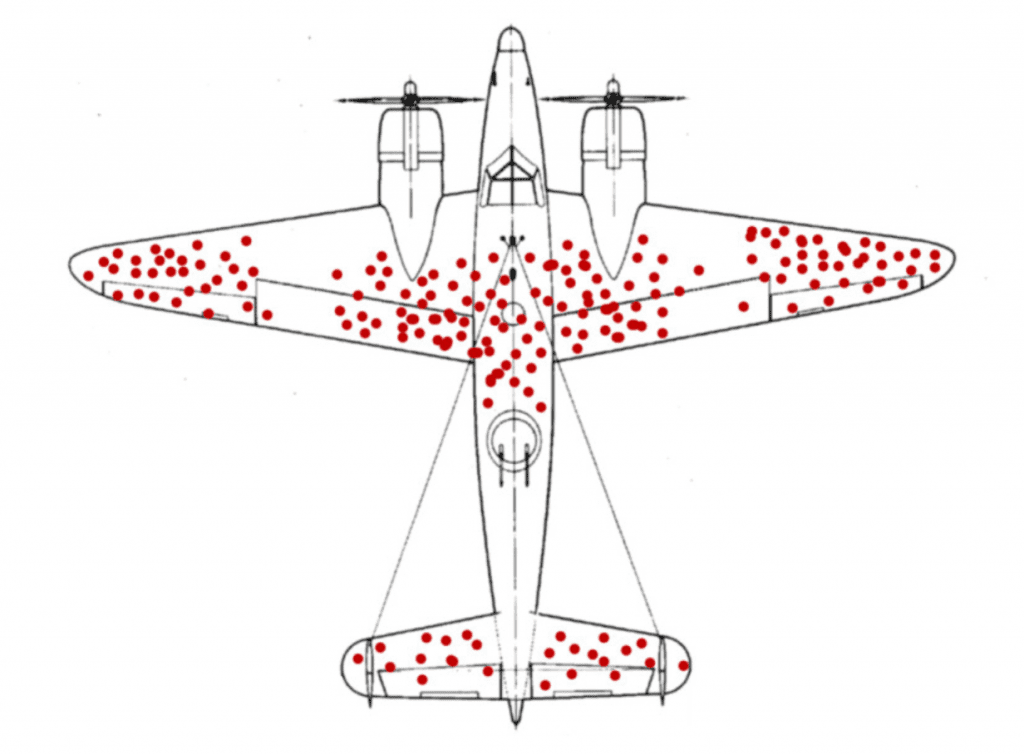
2차 세계대전 당시의 일화라고 알려진 전투기 장갑 보강에 대한 이야기가 생존자 편향 오류의 대표적인 사례입니다. 전투에 출격하는 전투기들의 생존율을 높이기 위해 당시 전투에서 귀환한 전투기들의 피탄 부위를 조사했더니 위 그림과 같은 결과를 얻었습니다. 대부분의 피탄 흔적이 동체와 날개 부분에 집중되어 있다면, 우리는 어느 부위의 장갑을 보강해야 할까요? 정답은 ‘알 수 없다’입니다. 위의 데이터는 ‘전투에서 살아 돌아온’ 전투기만을 조사한 것이기 때문에 전투에서 살아 돌아오지 못한 전투기들의 데이터는 알 수 없기 때문입니다. 이처럼 우리가 분석하는 데이터가 편향을 가지게 되면, 분석 결과 자체를 신뢰할 수 없게 됩니다.
참고 도서>>양승화 저, <그로스해킹>
